Publications
In Situ AI Prototyping: Infusing Multimodal Prompts into Mobile Settings with MobileMaker
Savvas Petridis*,
Michael Xieyang Liu*, Alexander J Fiannaca, Vivian Tsai,
Michael Terry,
Carrie J. Cai.
VL/HCC 2024, IEEE Symposium on Visual Languages and Human-Centric Computing.
* denotes equal contribution.
ConstitutionalExperts: Training a Mixture of Principle-based Prompts
Savvas Petridis*,
Benjamin Wedin*, Ann Yuan*, James Wexler, Nithum Thain.
ACL 2024, Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics.
* denotes equal contribution.
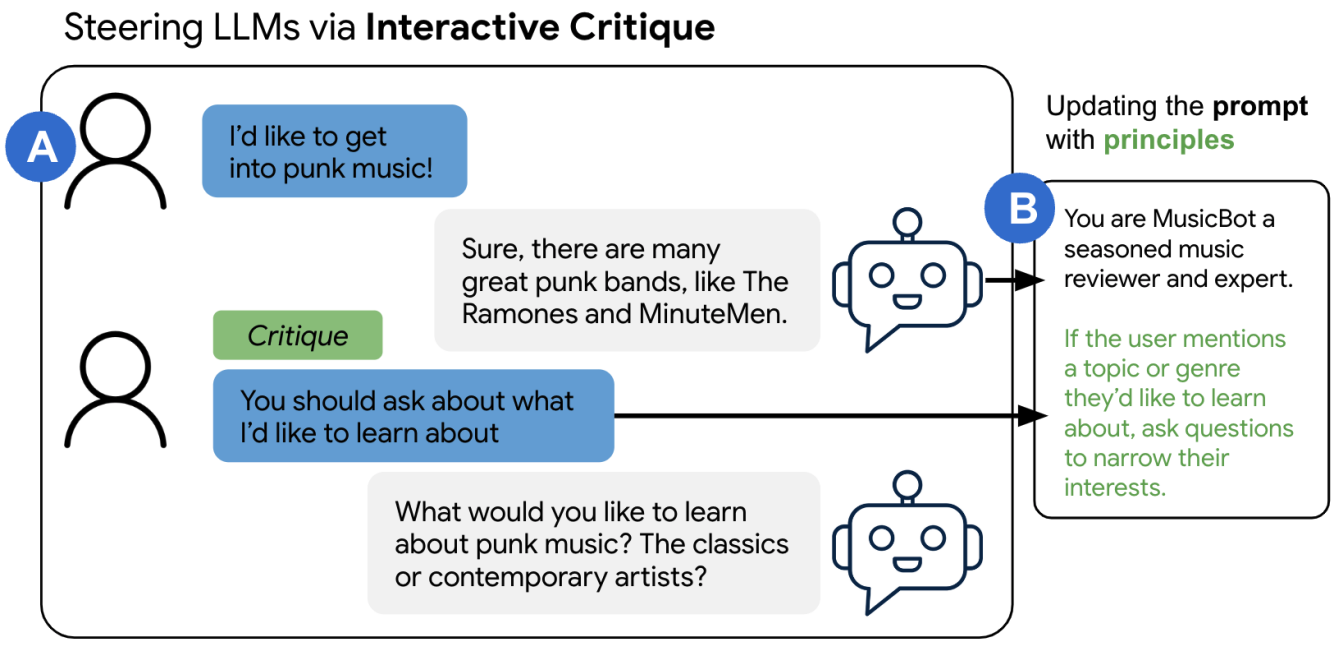
ConstitutionMaker: Interactively Critiquing Large Language Models by Converting Feedback into Principles
Savvas Petridis,
Benjamin Wedin, James Wexler, Aaron Donsbach,
Mahima Pushkarna,
Nitesh Goyal,
Carrie J. Cai,
Michael Terry.
IUI 2024, ACM Conference on Intelligent User Interfaces.
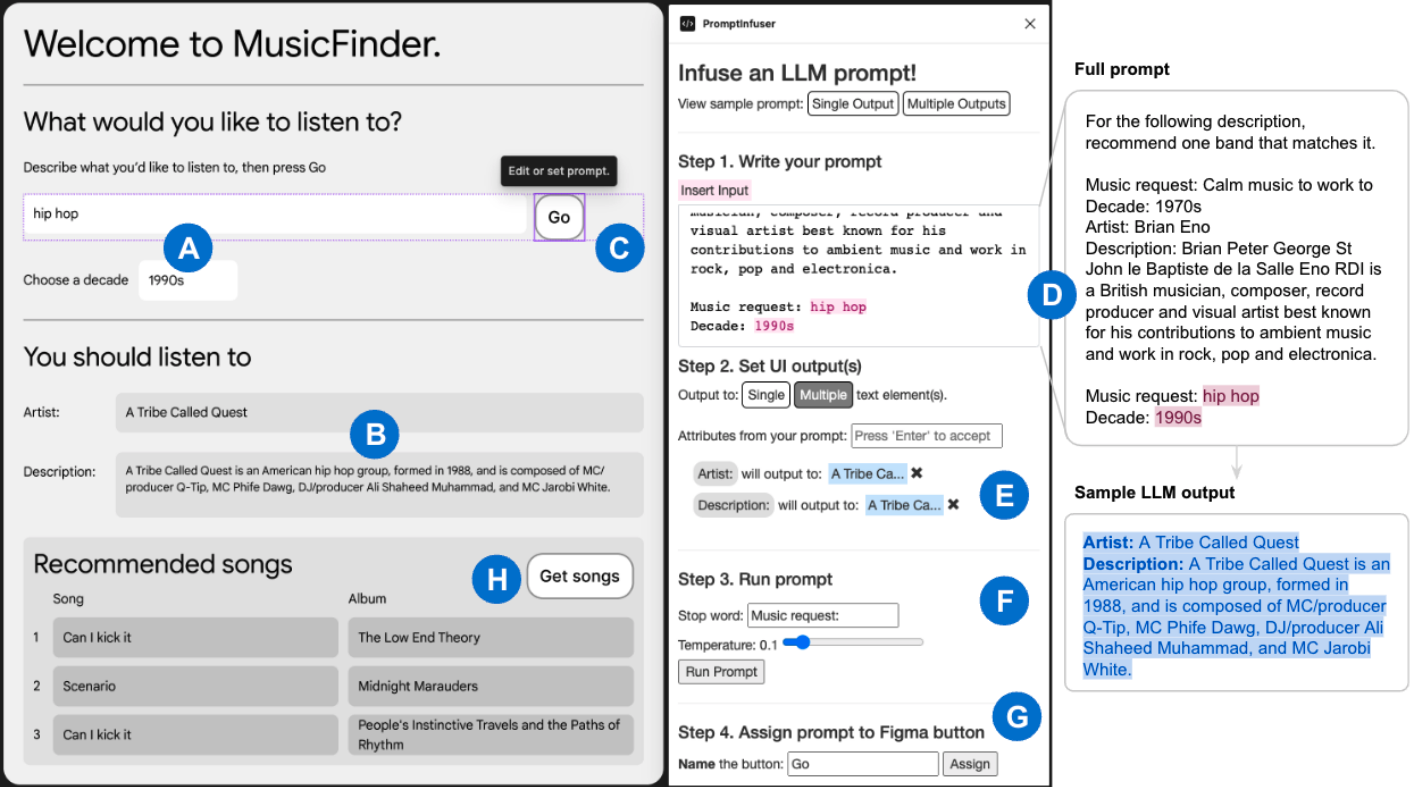
PromptInfuser: How Tightly Coupling AI and UI Design Impacts Designers' Workflows
Savvas Petridis,
Michael Terry,
Carrie J. Cai.
DIS 2024, ACM Conference on Designing Interactive Systems.
Visualizing Linguistic Diversity of Text Datasets Synthesized by Large Language Models
Emily Reif,
Minsuk Kahng,
Savvas Petridis.
VIS 2023, IEEE Visualization and Visual Analytics Conference.
PromptInfuser: Bringing User Interface Mock-ups to Life with Large Language Models
Savvas Petridis,
Michael Terry,
Carrie J. Cai.
CHI 2023 Late Breaking Work, ACM Conference on Human Factors in Computing Systems.
AngleKindling: Supporting Journalistic Angle Ideation with Large Language Models
Savvas Petridis,
Nicholas Diakopoulos,
Kevin Crowston,
Mark Hansen,
Keren Henderson,
Stan Jastrzebski,
Jeffrey V. Nickerson,
Lydia B. Chilton.
CHI 2023, ACM Conference on Human Factors in Computing Systems.
PopBlends: Strategies for Conceptual Blending with Large Language Models
Sitong Wang,
Savvas Petridis,
Taeahn Kwon,
Xiaojuan Ma,
Lydia B. Chilton.
CHI 2023, ACM Conference on Human Factors in Computing Systems.
TastePaths: Enabling Deeper Exploration and Understanding of Personal Preferences in Recommender Systems
Savvas Petridis,
Nediyana Daskalova,
Sarah Mennicken,
Samuel F. Way,
Paul Lamere,
Jennifer Thom.
IUI 2022, ACM Conference on Intelligent User Interfaces.
SymbolFinder: Brainstorming Diverse Symbols Using Local Semantic Networks
Savvas Petridis,
Hijung Valentina Shin,
Lydia B. Chilton.
UIST 2021, ACM Symposium on User Interface Software and Technology.
Human Errors in Interpreting Visual Metaphor
Savvas Petridis and
Lydia B. Chilton.
C&C 2019, ACM Conference on Creativity and Cognition.
VisiBlends: A Flexible Workflow for Visual Blends
Lydia B. Chilton,
Savvas Petridis,
Maneesh Agrawala.
CHI 2019, ACM Conference on Human Factors in Computing Systems.
Where is your Evidence: Improving Fact-checking by Justification
Tariq Alhindi,
Savvas Petridis,
Smaranda Muresan.
FEVER (Fact Extraction and Verification) Workshop at EMNLP 2018.
AMuSe: Large-scale WiFi video distribution - Experimentation on the ORBIT testbed
Varun Gupta, Raphael Norwitz,
Savvas Petridis, Craig Gutterman, Gil Zussman, Yigal Bejerano.
Demo description in Proc. IEEE INFOCOM'16, 2016.
WiFi multicast to very large groups - experimentation on the ORBIT testbed
Varun Gupta, Raphael Norwitz,
Savvas Petridis, Craig Gutterman,
Gil Zussman, Yigal Bejerano.
Demo at IEEE LCN'15, 2015.